
Всем привет,
На просторах интернета я обнаружил один интересный парсер, я добавил описание и немного доработав решил презентовать вам.
Проект объемный поэтому запаситесь терпением.
Лень читать статью вот готовый проект: [download-attachment id=»2931″ title=»SuperParser на С#»]
Поехали,
1) Создаем проект WinForm, назовем его «SuperParser».
2) Сразу заходим в свойства формы и меняем св-ву Text значение на «SuperParser», size выставляем width 800 на height 600 + FormBorderStyle = «FixedSingle»
3) Теперь кидаем на форму listBox, фиксируем его по левому краю, называем его ListTitles(св-во name)
4) Справа кидаем 2 элемента numericUpDown и 2 label к ним, а также 4 кнопки(элемент button)
-первому numbericUpDown меняем св-во name на numericUpDownStart
-второму numbericUpDown меняем св-во name на numericUpDownEnd
-первая кнопку у нас будет подгружать заголовки с сайта habr.ru, поэтому кнопка будет называться buttonHabr, а св-во text=»Habr».
-вторая кнопка у нас будет подгружать заголовки с сайта freelansim.ru, а св-во text=»Freelansim», name=buttonFreelansim
-третья кнопка будет отвечать за очистку listBox, ее назовем buttonClear, а св-во text=»Очистить».
-про четвертую кнопку мы поговорим чуть позже, пока назовем ее «Завершить», а св-во name buttonClose, text=»Завершить»
Форма сейчас выглядит так:
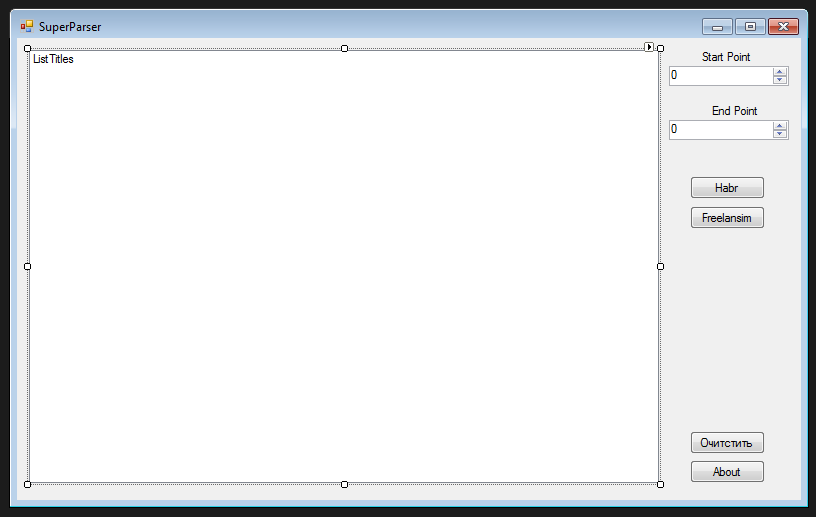
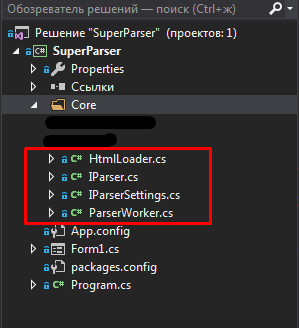
5) Так теперь начнем писать ядро нашего парсера, создадим папку в корне проекта и назовем ее Core, все последующие классы и интерфейсы будут храниться в этой папке.
6) Ядро будет состоять из 2 классов(ParserWorker,HtmlLoader) и 2-х интерфейсах (IParser,IParserSettings). Создадим их.
7) Начнем с интерфейса IParserSettings в нем будет 4 св-в, это фактически настройки будущего парсера — url,динамический постфикс(страницы), в CurrentId будет поставлять id страницы, св-вам StartPoint,EndPoint значение будет присваиваться через конструктор реализующего интерфейс класса. Вот его код
namespace SuperParser
{
interface IParserSettings
{
string BaseUrl { get; set; } //url сайта
string Postfix { get; set; } //в постфикс будет передаваться id страницы
int StartPoint { get; set; } //c какой страницы парсим данные
int EndPoint { get; set; } //по какую страницу парсим данные
}
}
8) Так, самое время подключать библиотеку AngleSharp с помощью который собственно будет распаршивать HTML страницы.
9) Переходим в управление nuget пакетами
10) Устанавливаем библиотеку.
11) Теперь переходим к интерфейсу IParser, это обобщенный интерфейс, в качестве обобщенного параметра указываем T где T — это объект ссылочного типа, интерфейс содержит единственный, но очень важный метод Parse, в него будет передаваться код страницы после чего будет производиться анализ кода и поиск содержимого HTML элементов. Вот его код:
using AngleSharp.Html.Dom;
namespace SuperParser
{
interface IParser<T> where T : class //класс реализующие этот интерфейс смогут возвращаться данные любого ссылочного типа
{
T Parse(IHtmlDocument document); // тип T при реализации будет заменяться на любой другой тип
}
}
12) Далее переходим в класс HtmlLoader, этот класс будет получать настройки(url и постфикс) и загружать содержимое HTML страницы, я оставил подробные комментарии по коду. Вот собственно код:
using System.Threading.Tasks;
using System.Net;
using System.Net.Http;
namespace SuperParser
{
//Предназначение этого класса загружать код HTML страницы из указанных настроек парсера.
class HtmlLoader
{
readonly HttpClient client; //для отправки HTTP запросов и получения HTTP ответов.
readonly string url; //сюда будем передовать адрес.
public HtmlLoader(IParserSettings settings)
{
client = new HttpClient();
client.DefaultRequestHeaders.Add("User-Agent", "C# App"); //Это для индентификации на сайте-жертве.
url = $"{settings.BaseUrl}/{settings.Postfix}/"; //Здесь собирается адресная строка
}
public async Task<string> GetSourceByPage(int id) // id - это id страницы
{
string currentUrl = url.Replace("{CurrentId}", id.ToString());//Подменяем {CurrentId} на номер страницы
HttpResponseMessage responce = await client.GetAsync(currentUrl); //Получаем ответ с сайта.
string source = default;
if (responce!=null && responce.StatusCode == HttpStatusCode.OK)
{
source = await responce.Content.ReadAsStringAsync(); //Помещаем код страницы в переменную.
}
return source;
}
}
}
13) Теперь займемся самым объемным классом ParserWorker, он будет обобщенным, в качестве обобщенного параметра может использоваться только объект ссылочного типа. Этот класс будет получать код страницы через HtmlLoader, после чего разбирать страницу и возвращать содержимое нужных элементов. Я так же оставил комментарии по коду, на мой взгляд все должно быть понятно, если нет то пишите распишу подробнее. Вот код:
using AngleSharp.Html.Dom;
using AngleSharp.Html.Parser;
using System;
namespace SuperParser.Core
{
class ParserWorker<T> where T : class
{
IParser<T> parser;
IParserSettings parserSettings; //настройки для загрузчика кода страниц
HtmlLoader loader; //загрузчик кода страницы
bool isActive; //активность парсера
public IParser<T> Parser
{
get { return parser; }
set { parser = value; }
}
public IParserSettings Settings
{
get { return parserSettings; }
set
{
parserSettings = value; //Новые настройки парсера
loader = new HtmlLoader(value); //сюда помещаются настройки для загрузчика кода страницы
}
}
public bool IsActive //проверяем активность парсера.
{
get { return isActive; }
}
//Это событие возвращает спаршенные за итерацию данные( первый аргумент ссылка на парсер, и сами данные вторым аргументом)
public event Action<object, T> OnNewData;
//Это событие отвечает информирование при завершении работы парсера.
public event Action<object> OnComplited;
//1-й конструктор, в качестве аргумента будет передеваться класс реализующий интерфейс IParser
public ParserWorker(IParser<T> parser)
{
this.parser = parser;
}
public void Start() //Запускаем парсер
{
isActive = true;
Worker();
}
public void Stop() //Останавливаем парсер
{
isActive = false;
}
public async void Worker()
{
for (int i = parserSettings.StartPoint; i <= parserSettings.EndPoint; i++)
{
if (IsActive)
{
string source = await loader.GetSourceByPage(i); //Получаем код страницы
//Здесь магия AngleShap, подробнее об интерфейсе IHtmlDocument и классе HtmlParser,
//можно прочитать на GitHub, это интересное чтиво с примерами.
HtmlParser domParser = new HtmlParser();
IHtmlDocument document = await domParser.ParseDocumentAsync(source);
T result = parser.Parse(document);
OnNewData?.Invoke(this, result);
}
}
OnComplited?.Invoke(this);
isActive = false;
}
}
}
14) Первый сайт который мы будем парсить будет hadr.ru, а спаршивал мы с него будем заголовки.
15) В папке Core создадим папку Habr
16) В ней создадим класс HabrSettings
17) Указываем, что класс будет реализовывать интерфейс IParserSettings
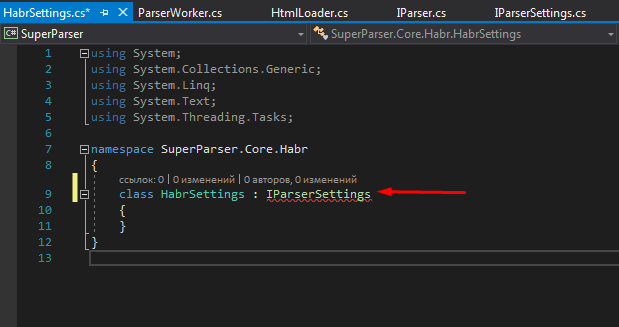
18) Собственно, реализовываем св-ва IParserSettings
public string BaseUrl { get; set; } = "https://habr.ru"; //здесь прописываем url сайта.
public string Prefix { get; set; } = "page{CurrentId}"; //вместо CurrentID будет подставляться номер страницы
public int StartPoint { get; set; }
public int EndPoint { get; set; }
19) Так как первая и последняя страница будет указываться из формы нам понадобиться конструктор для инициализации св-ва StartPoint и EndPoint
public HabrSettings(int start, int end)
{
StartPoint = start;
EndPoint = end;
}
20) Итого работа над этим классом завершена, выглядит он так.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace SuperParser.Core.Habr
{
class HabrSettings : IParserSettings
{
public HabrSettings(int start, int end)
{
StartPoint = start;
EndPoint = end;
}
public string BaseUrl { get; set; } = "https://habr.ru"; //здесь прописываем url сайта.
public string Prefix { get; set; } = "page{CurrentId}"; //вместо CurrentID будет подставляться номер страницы
public int StartPoint { get; set; }
public int EndPoint { get; set; }
}
}
21) Теперь создаем класс, из которого будем парсить сайт назовем его HabrParser, он у нас будет реализовывать интерфейс IParser, в качестве T у нас будет массив строк.
22) Теперь самое главное, нам нужно зайти на сайт habr.ru и посмотреть в каком элементе хранятся заголовки.
23) Заходим на сайт и нажимаем F12, далее делаем поиск по элементам и получаем результат, заголовки хранятся в class=»post__title_link», который находится в теге <a>
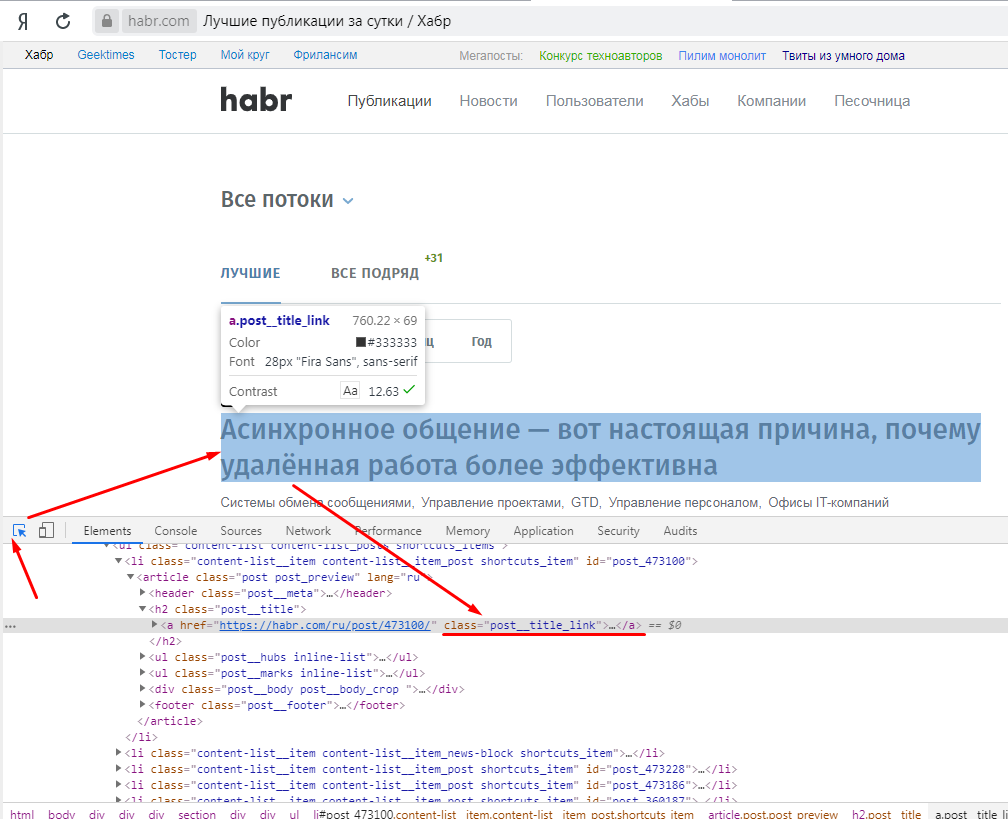
24) Идем обратно в код, пишем следующее:
public string[] Parse(IHtmlDocument document)
{
//Для хранения заголовков
List<string> list = new List<string>();
//Здесь мы получаем заголовки
IEnumerable<IElement> items = document.QuerySelectorAll("a")
.Where(item => item.ClassName!= null && item.ClassName.Contains("post__title_link"));
foreach (var item in items)
{
//Добавляем заголовки в коллекцию.
list.Add(item.TextContent);
}
return list.ToArray();
}
25) В общем то всё, возвращаемся к форме, для начала объявим переменную типа ParserWorker<string[]> назовем parser_habr, после чего нам предложат добавить using SuperParser.Core; — соглашаемся, а за одно добавим и using SuperParser.Core.Habr;
26) В конструкторе формы после InitializeComponent(); пишем следующее:
parser_habr = new ParserWorker<string[]>(new HabrParser()); //По заврешению работы парсера будет появляться уведомляющее окно. parser_habr.OnComplited += Parser_OnComplited; //Заполняем наш listBox заголовками parser_habr.OnNewData += Parser_OnNewData;
27) За конструктором формы реализовываем методы Parser_OnComplited и Parser_OnNewData
public void Parser_OnComplited(object o) { MessageBox.Show("Работа завершена!"); }
public void Parser_OnNewData(object o, string[] str) { ListTitles.Items.AddRange(str); }
28) Теперь необходимо создать обработчик для кнопки Habr, переходим на форму кликаем по ней два раза переходим в код, пишем следующее:
//Настройки для парсера parser_habr.Settings = new HabrSettings((int)numericUpDownStart.Value, (int)numericUpDownEnd.Value); //Парсим! parser_habr.Start();
29) В принципе, уже сейчас можно зайти и проверить как парсятся заголовки.
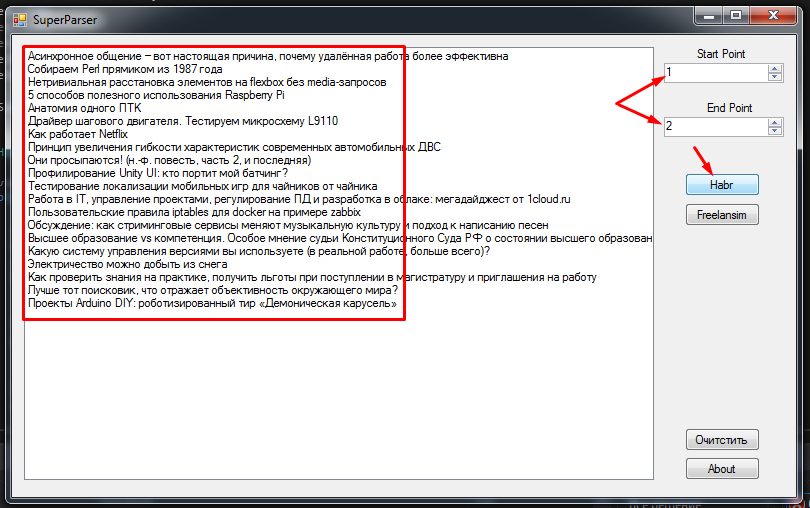
30) Отлично парсер работает, теперь нужно написать обработчики для кнопок очистить и about, они будут выглядеть так:
private void buttonClear_Click(object sender, EventArgs e)
{
//Очищаем listBox
ListTitles.Items.Clear();
}
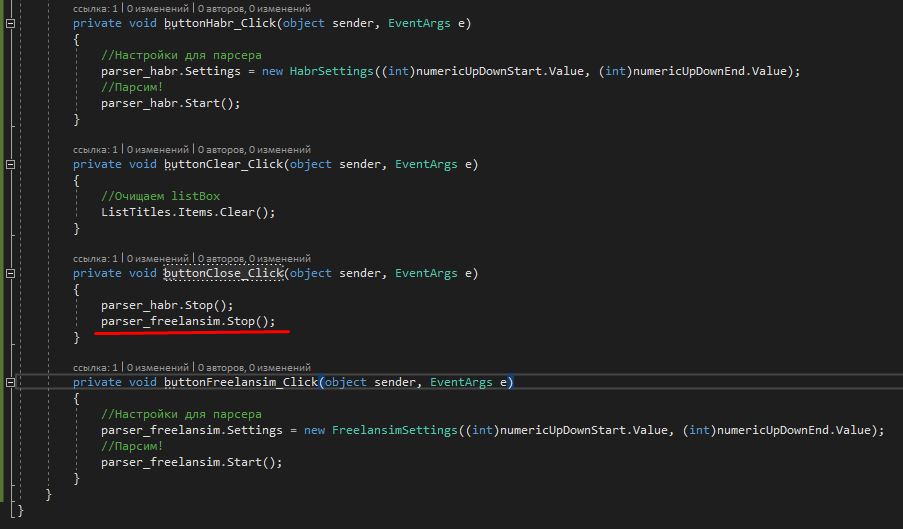
private void buttonClose_Click(object sender, EventArgs e)
{
parser_habr.Stop();
}
31) Теперь по аналогии спарсим заголовки заданий на сайте Freelansim.ru
32) Создаем в папке Core папку Freelansim, а в ней класс FreelansimSettings, который выглядит так:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace SuperParser.Core.Freelansim
{
class FreelansimSettings : IParserSettings
{
public FreelansimSettings(int start,int end)
{
StartPoint = start;
EndPoint = end;
}
public string BaseUrl { get; set; } = "https://freelansim.ru/tasks";
public string Prefix { get; set; } = "page={CurrentId}";
public int StartPoint { get; set; }
public int EndPoint { get; set; }
}
}
33) Теперь создает класс FreelansimParser, вот его код:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using AngleSharp.Dom;
using AngleSharp.Html.Dom;
namespace SuperParser.Core.Freelansim
{
class FreelansimParser : IParser<string[]>
{
public string[] Parse(IHtmlDocument document)
{
List<string> list = new List<string>();
IEnumerable<IElement> items = document.QuerySelectorAll("div")
.Where(item => item.ClassName != null && item.ClassName.Contains("task__title"));
foreach (var item in items)
{
list.Add(item.TextContent);
}
return list.ToArray();
}
}
}
34) Переходим на форму кликаем 2 раза по кнопке Freelansim,пишем в нее следующее:
private void buttonFreelansim_Click(object sender, EventArgs e)
{
//Настройки для парсера
parser_freelansim.Settings = new HabrSettings((int)numericUpDownStart.Value, (int)numericUpDownEnd.Value);
//Парсим!
parser_freelansim.Start();
}
35) Теперь поднимаем выше объявляем переменную parser_freelansim и инициализируем ее по аналогии с parser_habr
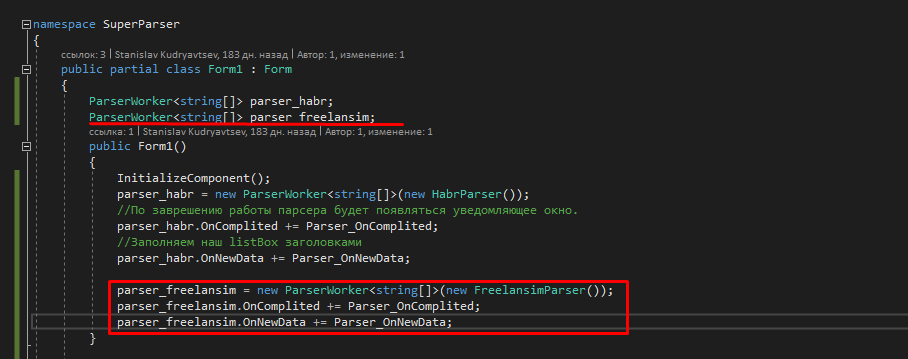
36) Проверяем как парсится freelansim.ru
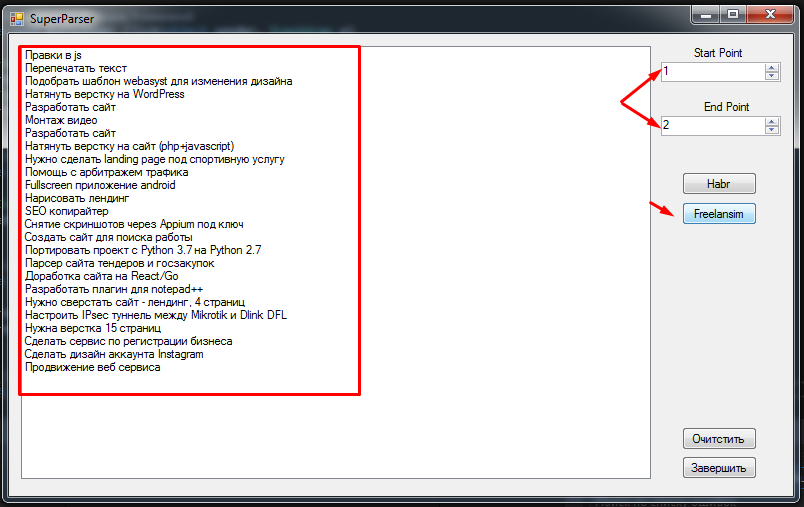
С минимальными изменения с помощью этого парсера можно распарсить практически любой сайт именно так много заморочек с обобщением.
Если дошел до конца, ставь лайк!
Да это прям праздник какой то ))) Очень любопытный пример)))) Спасибо за урок. Очень редко встретишь нормальный туториал для парсера на шарпе )))
Спасибо за «теплые» слова.
Большое спасибо. Сейчас все больше людей начинает понимать что C# язык будущего и постепенно начинает появляться много годных примеров.
Спасибо за теплые слова.
Не могу разобраться как вывести 2 элемента, допустим не только заголовок, а заголовок и дату публикации.
Приветствую, понимаю, что поздно ответил, но отвечаю на тот случай, если кого то еще это интересует, самый простой способ, внести изменения в HabrParser: listPostTime = new List (); //New listHeader = new List (); //Update listResult = new List (); //New
public string[] Parse(IHtmlDocument document)
{
List
List
List
IEnumerable itemsHeaders= document.QuerySelectorAll(«a») itemsPostTime = document.QuerySelectorAll(«*») //New
.Where(item => item.ClassName!= null && item.ClassName.Contains(«post__title_link»));
IEnumerable
.Where(item => item.ClassName != null && item.ClassName.Contains(«post__time»));
foreach (var item in itemsHeaders) //Update
{
listHeader.Add(item.TextContent);
}
foreach (var item in itemsPostTime) //New
{
listPostTime.Add(item.TextContent);
}
int counter = 0;
foreach (var item in listHeader) //New
{
listResult.Add(item+»(«+listPostTime[counter]+»)»);
counter++;
}
return listResult.ToArray();
}
Добрый день, у меня почему то не получается спарсить с этого сайта https://banketservice.ru/
Я вставляю свой сайт,свои теги. И ничего не работает!В чем причина?
Изучайте код, в нем все есть! если реально не получается напишите мне на rabota683@gmail.com постараюсь помочь.
В классе ParserWorker ошибка — на 70 строчке retern выйдет из функции и цикл будет выполнен всего один раз
Приветствую, согласен, исправил, так же обратите внимание что baseUrl habr изменился, тоже поправил.
Спасибо! Так понятно и подробно!
Спасибо за «теплые» слова.
исправте ошипки:
//сюда будем передовать адрес.
Присоединяюсь к благодарной публике, все по полочкам. А как сделать чтобы при повторном парсинге (повторно нажимаем кнопочку Хабр) в список добавлялись только новые заголовки (свежие изменения на сайте) ,именно добавлялись, а не полный «рефреш». Спасибо!!
в классе HabrSettings public string Prefix поменять на Postfix, в ParserWorker лишний public ParserWorker(HabrParser habrParser)
{
}
как мне кажется
а как мультипроцессорный парсинг сделать(10000 страниц)?
а как сделать чтобы этот парсер мог ещё атрибуты выдёргивать? например href ссылки
Отредактируйте пожалуйста ссылку на рабочий проект.